[SQL] 튜닝 - sql 처리 과정과 I/O🔥
SQL튜닝의 정의
SQL튜닝이란?
SQL 문을 최적화하여 빠른 시간내에 원하는 결과값을 얻기 위한 작업
튜닝 자체는 기술적으론 쉽다
튜닝이 어렵다고 느끼는 것은 업무를 모르기 때문
옵티마이저
SQL을 가장 빠르고 효율적으로 수행할 최적(최저비용)의 처리경로를 생성해주는 핵심 엔진
프로시저
쿼리가 실행하면서 원하는 결과를 만들 때, 절차를 만들고 그 절차대로 결과를 만든다.
즉, 프로시저는 특정한 업무를 수행하기 위한 절차를 뜻함.
파싱(parsing) - 자르기
- 파싱트리 생성 : SQL문을 이루는 개별 구성요소를 분석해서 파싱트리 생성
- Syntax 체크 : 문법적 오류가 없는지 확인
- Semantic 체크 : 의미상 오류가 없는지 확인
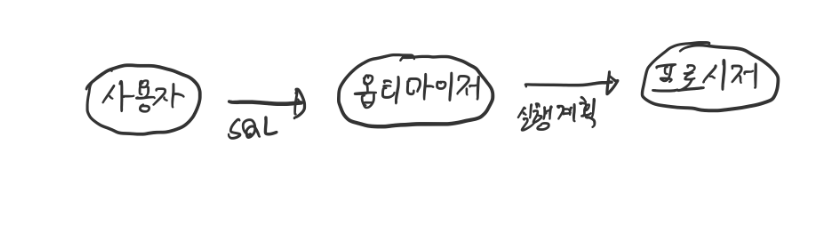
사용자가 sql명령을 내리면 DB의 옵티마이저가 처리
처리과정
- 문법체크
- 구문분석
- 최적화
- 자동
- rule-base : 무엇이 먼저이고 나중인지 정해져있음 (잘 사용안함. 성능 ↓)
- cost-base : 통계기반. 실제로 쿼리를 수행하는 비용의 통계를 재서 비용이 적은 것으로 알아서 해줌
- 수동
- 힌트(hint)
- 자동
- 번역
힌트(hint)
주석을 사용해서 힌트를 줄 수 있음 (Java에서 애너테이션 같은 역할)
사용법
-- 1번
SELECT /*+ INDEX(A 고객_PK)*/
고객명, 연락처, 주소, 가입일시
FROM 고객 A
WHERE 고객ID = ‘00000008’
-- 2번
SELECT --+ INDEX(A 고객_PK) -- 가급적 사용x
고객명, 연락처, 주소, 가입일시
FROM 고객 A
WHERE 고객ID = ‘00000008’주의사항
- 힌트와 힌트 사이에 ' , ' 사용 x
- 테이블을 지정할 때 스키마명 명시 x
- FROM절 테이블명 옆에 ALIAS 지정시, 힌트에도 반드시 ALIAS 사용
바인드변수의 중요성
SELECT * FROM EMP WHERE ID = 'asdf';
select * from emp where id = 'qwer';위 두개의 문장은 다르다.
대소문자를 통일하면 데이터 값도 변경이 이뤄지기 때문에 캐싱을 쓸 수 없다.
그래서 사용하는 것이 PreparedStatement
// PreparedStatement 바인드변수
// 하나로 통일
String SQLStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = ?";이렇게 사용할 경우의 장점
- 보안에 좋음
- 코드 재사용성이 높음
- sql인젝션을 막아줌
여기까지의 정리
사용자가 sql명령을 내리면
1. 파싱을한다.
2. 트리를 만든다.
3. 문법확인, 구문분석
4. 최적화 (자동 or 수동)
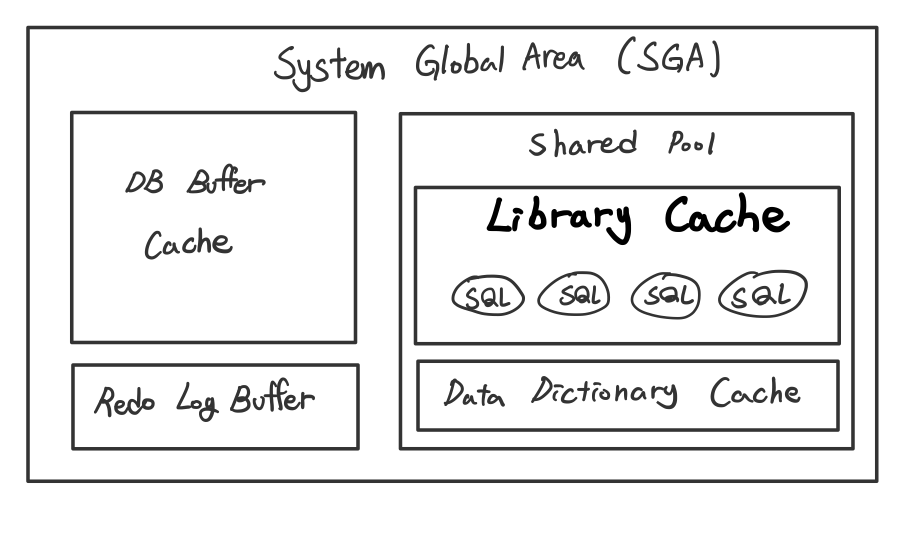
SGA
서버 프로세스와 백그라운드 프로세스가 공통으로 엑세스 하는 데이터와 제어구조를 캐싱하는 메모리 공간
Library Cache
SQL파싱, 최적화, 로우소스 생성 과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해두는 메모리 공간
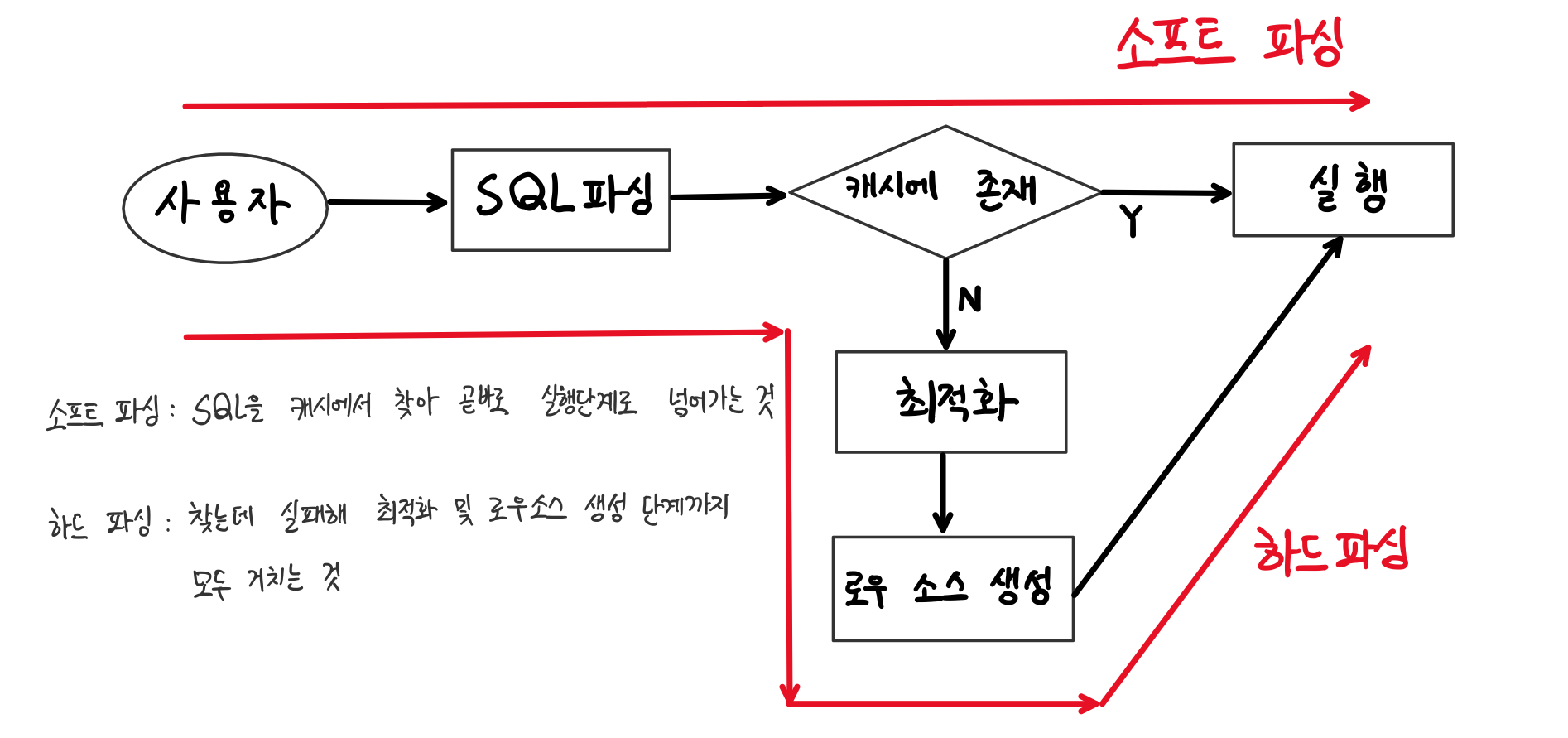
소프트 파싱(soft parsing) & 하드 파싱(hard parsing)
- 소프트파싱 : SQL을 캐시에서 찾아 곧바로 실행단계로 넘어가는 것
- 하드파싱 : 찾는데 실패해 최적화 및 로우소스 생성 단계까지 모두 거치는 것
데이터베이스 저장 구조

- 블록 : 데이터를 읽고 쓰는 단위
- 익스텐트 : 공간을 확장하는 단위. 연속된 블록 집합.
- 세그먼트 : 데이터 저장공간이 필요한 오브젝트
- 테이블스페이스 : 세그먼트를 담는 컨테이너. 모든 오브젝트를 담을 수 있는 공간
- 데이터파일 : 디스크 상의 물리적인 os파일
시퀀셜 액세스(sequential access) & 랜덤 액세스(random access)
- 시퀀셜 액세스 : 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식
- 랜덤 액세스 : 논리적, 물리적인 순서를 따르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식
논리적 I/O & 물리적 I/O
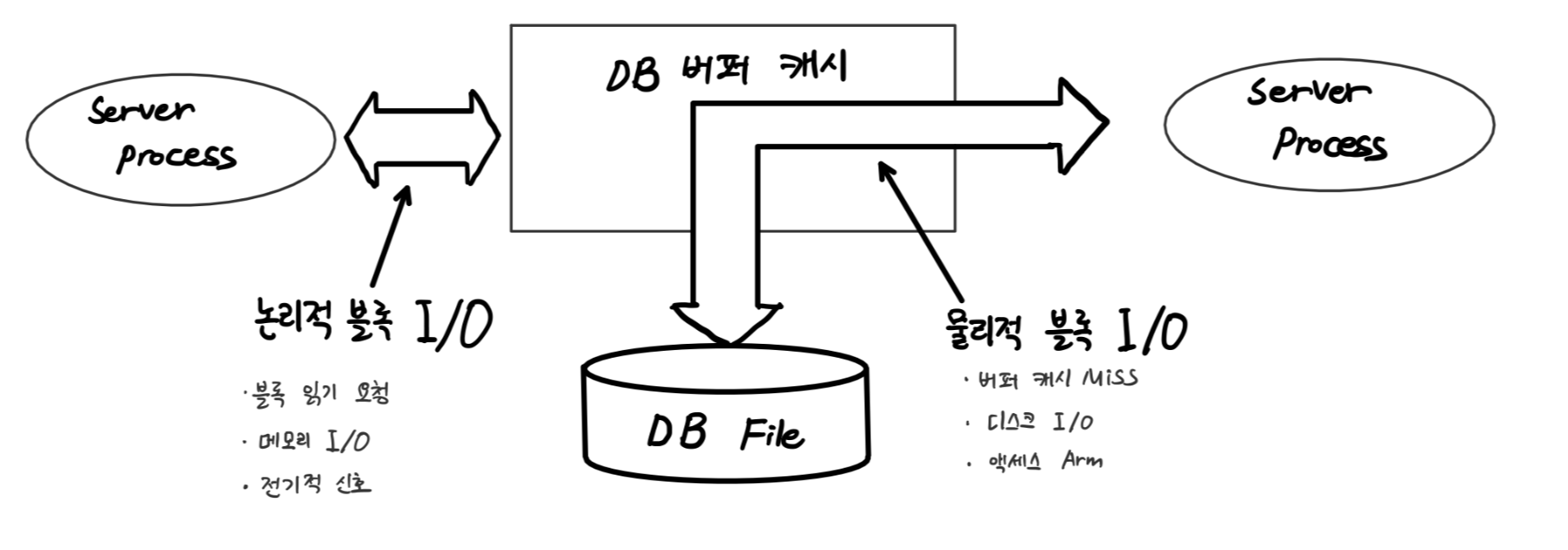
- 논리적 I/O : 캐시에서 가져옴
- 물리적 I/O : 캐시에 없기 때문에 디스크까지 가서 가져옴 (시간이 오래 걸림)
싱글블록 I/O & 멀티블록 I/O
- 싱글블록 I/O : 하나씩 나르는 것 (랜덤 액세스)
- 멀티블록 I/O : 여러개씩 나르는 것 (시퀀셜 액세스)
Table Full Scan (풀 스캔) & Index Range Scan (인덱스 스캔) - 테이블에 저장되는 데이터를 읽는 방식
- 풀 스캔 : 테이블에 속한 블록 전체를 읽어서 사용자가 원하는 데이터를 찾는 방식
- 인덱스 스캔 : 인덱스에서 일정량을 스캔하면서 얻은 RowID로 테이블 레코드를 찾아가는 방식
***ROWID는 테이블 레코드가 디스크 상에 어디 저장되었는지 가리키는 위치 정보***
풀 스캔이 성능이 안좋을 것 같지만 사실은 그렇지 않다.
찾아야 하는 데이터가 상당히 많다면 오히려 풀 스캔의 성능이 좋다.
캐시 탐색 매커니즘

래치 & 락
캐시버퍼 체인 래치
대량의 데이터를 읽을 때 모든 블록에 대해 해시 체인을 탐색한다.
해시 체인을 스캔하는 동안 다른 프로세스가 체인 구조를 변경하는 일이 생기면 곤란하기 때문에 이를 막기 위해 체인 래치가 존재한다.
체인 앞쪽에 자물쇠가 있다고 생각하면 된다. 자물쇠를 열 수 있는 키를 획득한 프로세스만 체인으로 진입 가능
버퍼 락
읽고자하는 블록을 찾았다면 캐시버퍼 체인래치를 곧바로 해제한다. 그런데 래치를 해제하면 버퍼블록 데이터를 일고 쓰는 도중 후행 프로세스가 같은 블록에 접근해 데이터를 읽고 쓴다면 데이터 정합성에 문제가 생길 수 있다. 이를 방지하기 위해 버퍼락을 사용한다.
버허페더에 락을 설정함으로써 버퍼블록 자체에 대한 직렬화 문제를 해결하는 것이다.