
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 그룹함수
- 엔티티
- Spring data JPA
- 스프링
- 스프링 데이터 JPA
- TCP/IP
- index
- @MappedSuperclass
- Spring
- 친절한 SQL 튜닝
- 자바의 정석
- 데이터베이스
- 정렬
- JPQL
- 오라클
- SQL
- 페이징
- 컬렉션 조회 최적화
- 데이터모델링
- fetch join
- 스프링 컨테이너
- SQL 튜닝
- 값 타입
- DTO
- querydsl
- 성능최적화
- JPA
- 서브쿼리
- 페치조인
- INDEX SCAN
- Today
- Total
nu_s
[SQL] 튜닝 - 해시 조인🔥 본문
해시 조인 (Hash Join) - 해시맵을 이용한 조인
NL 조인은 인덱스를 이용한 조인 방식이므로 인덱스 구성에 따른 성능 차이가 심하다.
소트 머지 조인은 항상 양쪽 테이블을 정렬하는 부담이 있다.
해시 조인은 위와 같은 부담이 없다.
기본 메커니즘
해시 조인도 소트 머지 조인처럼 두 단계로 진행된다.
- Build 단계 : 작은 쪽 테이블을 읽어 해시 테이블(해시 맵)을 생성한다.
- Probe 단계 : 큰 쪽 테이블을 읽어 해시 테이블을 탐색하면서 조인한다.
작은 쪽 테이블로 해시 테이블을 생성하는 이유
해시 테이블은 PGA 영역에 할당된 Hash Area에 저장한다. 해시 테이블이 너무 커 PGA에 담을 수 없으면 Temp(디스크)에 저장한다.
물론 무조건적인건 아니다. (큰 테이블로 사용해도 되긴 함)
해시 조인을 사용할 때는 use_hash 힌트로 유도한다
select /*+ ordered use_hash(c) */
e.사원번호, e.사원명, e.입사일자
,c.고객번호, C.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000
;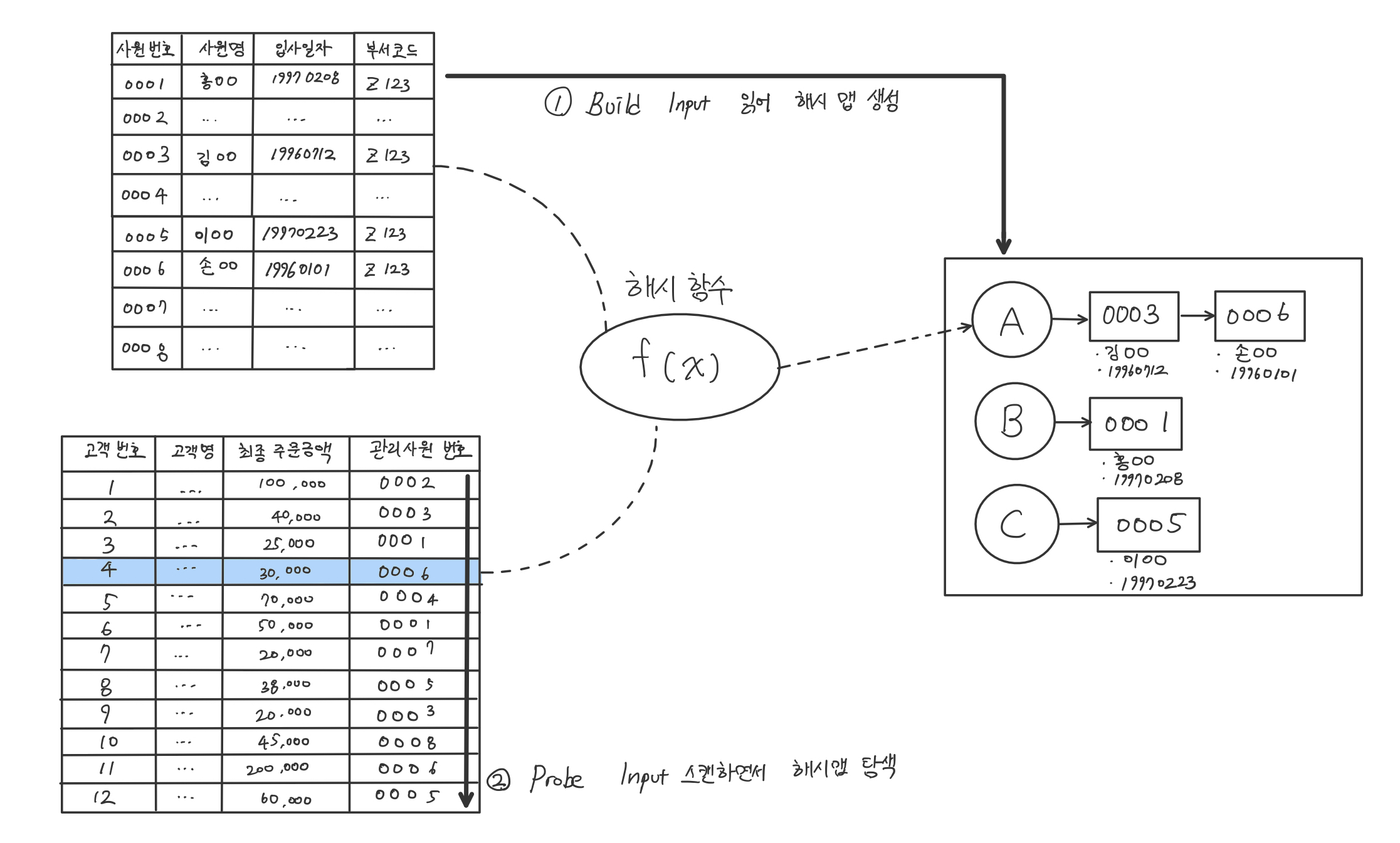
Build 단계 : 아래 조건에 해당하는 사원 데이터를 읽어 해시 테이블 생성. 이때 조인 컬럼인 사원번호를 해시 테이블 키 값으로 사용
select 사원번호, 사원명, 입사일자
from 사원
where 입사일자 >= '19960101'
and 부서코드 = 'Z123'
;Probe 단계 : 아래 조건에 해당하는 고객 데이터를 하나씩 읽어 위에 생성한 해시테이블을 탐색
select 고객번호, 고객명, 전화번호, 최종주문금액, 관리사원번호
from 고객
where 최종주문금액 >= 20000
;begin
for outer in (select 고객번호, 고객명, 전화번호, 최종주문금액, 관리사원번호
from 고객
where 최종주문금액 >= 20000)
loop -- outer 루프
for inner in (select 사원번호, 사원명, 입사일자
from PGA에_생성한_사원_해시맵
where 사원번호 = outer.관리사원번호)
loop -- inner 루프
dbms_output.put_line( ... );
end loop;
end loop;
end;
Build 단계에서 사용한 해시함수를 Probe 단계에서도 사용하므로 같은 사원번호를 입력하면 같은 해시 값을 반환한다.
해시 조인이 빠른 이유
이전 글에 올린 소트 머지 조인과 같이 PGA 영역에 할당하기 때문이다.
그런데 소트 머지 조인은 양쪽 집합을 정렬해야하는 부담이 있어 디스크에 쓰는 작업을 수반할 확률이 크다.
해시 조인은 NL 조인처럼 랜덤 액세스 부하가 없고, 소트 머지 조인처럼 정렬 부담도 없다.
세 개 이상 테이블 해시 조인
테이블 A, B, C 가 있다.
테이블을 조인하는 경로는 다음과 같이 두가지가 있다.

-- 경로 1
select * from A, B, C
where A.key = B.key
and B.key = C.key
-- 경로 2
select * from A, B, C
where A.key = B.key
and A.key = C.key이것을 다르게 생각해서 표현해보면
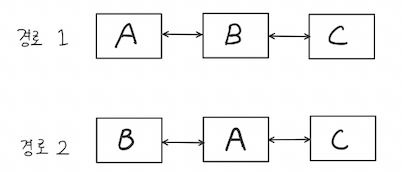
결국, 세 테이블을 조인하는 경로는 단 한가지로 좁혀진다.

-- 세 테이블에 대한 해시 조인을 제어할 때, leading 힌트를 지정해주면 된다.
select /*+ leading(T1, T2, T3) use_hash(T2) use_hash(T3) */ *
from T1, T2, T3
where T1.key = T2.key
and T2.key = T3.key
;
조인 메서드 선택 기준
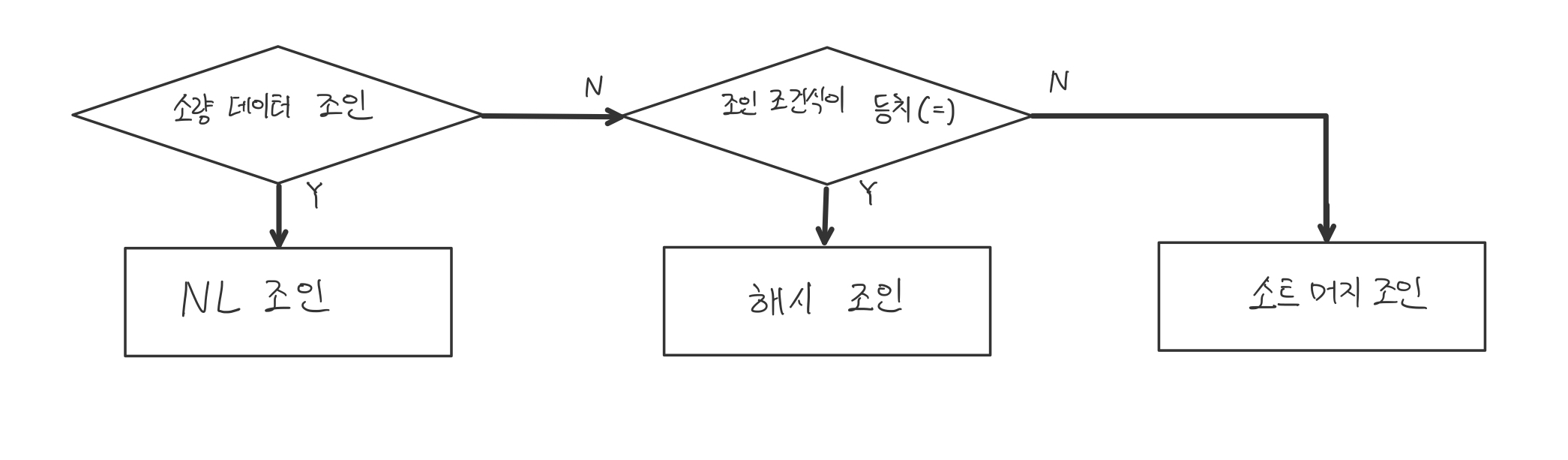
- 소량 데이터 조인할 때 - NL 조인
- 대량 데이터 조회할 때 - 해시 조인
- 대량 데이터 조인인데 조건식이 등치(=)가 아닐때 - 소트 머지 조인
수행 빈도가 매우 높은 쿼리에 대한 기준
- (최적화된) NL 조인과 해시 조인 성능이 같으면, NL 조인
- 해시 조인이 약간 더 빨라도 NL 조인
- NL 조인보다 해시 조인이 매우 빠른 경우, 해시조인
왜 NL 조인을 가장 먼저 고려해야할까?
NL 조인에 사용하는 인덱스는 영구적으로 유지하면서 재사용되는 자료구조인 반면
해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조다.
수행시간이 짧으면서 수행빈도가 매우 높은 쿼리를 해시 조인으로 처리하면 CPU와 메모리 사용률이 크게 증가한다.
'Data Base > DB Tunning' 카테고리의 다른 글
| [SQL] 튜닝 - 소트 튜닝🔥 (0) | 2023.08.20 |
|---|---|
| [SQL] 튜닝 - 서브쿼리 조인🔥 (0) | 2023.08.18 |
| [SQL] 튜닝 - 소트 머지 조인🔥 (0) | 2023.08.18 |
| [SQL] 튜닝 - NL 조인🔥 (0) | 2023.08.18 |
| [SQL] 튜닝 - 인덱스 튜닝 🔥 (0) | 2023.08.17 |


