
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 정렬
- 값 타입
- 스프링 데이터 JPA
- 컬렉션 조회 최적화
- 그룹함수
- Spring
- SQL 튜닝
- INDEX SCAN
- 자바의 정석
- TCP/IP
- 성능최적화
- 오라클
- querydsl
- 서브쿼리
- @MappedSuperclass
- 데이터모델링
- DTO
- JPQL
- SQL
- 페이징
- 스프링 컨테이너
- 페치조인
- JPA
- 친절한 SQL 튜닝
- index
- Spring data JPA
- 엔티티
- 데이터베이스
- 스프링
- fetch join
Archives
- Today
- Total
nu_s
[JPA 활용] 컬렉션 조회 최적화 - 페치 조인 & 페이징(Batch Size)🐱 본문
728x90
반응형
V3. 엔티티를 DTO로 변환 - 페치 조인 최적화
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
@GetMapping("/api/v3/orders")
public List<OrderDto> orderV3() {
List<Order> orders = orderRepository.findAllWithItem(); //새로운 메서드 생성
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
}
OrderRepository
public List<Order> findAllWithItem() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
)
}
실행하면 쿼리가 아래와 같이 나간다.
select
o1_0.order_id,
d1_0.delivery_id,
d1_0.city,
d1_0.street,
d1_0.zipcode,
d1_0.status,
m1_0.member_id,
m1_0.city,
m1_0.street,
m1_0.zipcode,
m1_0.name,
o1_0.order_date,
oi1_0.order_id,
oi1_0.order_item_id,
oi1_0.count,
i1_0.item_id,
i1_0.dtype,
i1_0.name,
i1_0.price,
i1_0.stock_quantity,
i1_0.artist,
i1_0.etc,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director,
oi1_0.order_price,
o1_0.status
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
join
delivery d1_0
on d1_0.delivery_id=o1_0.delivery_id
join
order_item oi1_0
on o1_0.order_id=oi1_0.order_id
join
item i1_0
on i1_0.item_id=oi1_0.item_id
이를 복사해서 H2에서 실행시켜보면

같은 order_id를 가진 데이터가 중복이 되는 것을 볼 수 있다.
원인
- Order와 OrderItem은 일대다 관계이기 때문에 한 Order에 해당하는 OrderItem의 개수만큼 중복이 된다.
해결 방법
- distinct를 사용하면 된다.
- 하지만 DB에서 distinct는 한 줄의 모든 컬럼이 동일해야 제거가 된다. -> DB 쿼리에서 distinct는 적용되지 않는다.
- JPA에서 자체적으로 애플리케이션에 가져온 데이터에서 Order 객체의 아이디가 같으면 중복을 제거한 뒤 반환해준다.
참고
- distinct를 사용하지 않았는데 포스트맨에서는 중복이 제거되어 나오는 경우가 있다. 그 이유는 다음과 같다.
- Spring boot 3.0 버전 이상은 Hibernate 6버전을 사용한다.
- Hibernate 6 버전은 페치 조인 사용 시 자동으로 중복 제거를 하도록 변경되었다고 한다.
- https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html#hql-distinct
Hibernate ORM User Guide
Starting in 6.0, Hibernate allows to configure the default semantics of List without @OrderColumn via the hibernate.mapping.default_list_semantics setting. To switch to the more natural LIST semantics with an implicit order-column, set the setting to LIST.
docs.jboss.org
장점
- V3의 장점은 페치 조인을 통해 쿼리를 한 번으로 줄여준다는 점이다.
- 기존 코드는 변하지 않고, 메서드만 변경하면 된다.
단점
- 컬렉션 페치 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하면 데이터가 부정합하게 조회될 수 있다.
- 컬렉션 페치 조인을 하면 페이징이 불가능하다.
public List<Order> findAllWithItem() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.setFirstResult(1)
.setMaxResults(100)
.getResultList();페이징처리를 한 후 실행하면

경고 로그가 뜬다.
- OneToMany 관계에서 페치 조인을 하면 One이 아닌 Many가 기준이 돼서 페이징을 한다. (Order가 아닌 OrderItem 기준이 된다.)
- 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다.(위험)
V3.1. 엔티티를 DTO로 변환 - 페이징과 한계 돌파
- V3에서 컬렉션 페치 조인은 페이징이 불가능하다는 점이 있었다.
- 컬렉션을 페치 조인하면 일대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
- 일대다에서 일(1)을 기준으로 페이징을 하는 것이 목적이다. 그런데 데이터는 다(N)을 기준으로 row가 생성된다.
- 이 경우 하이버에니트는 경고 로그를 남기고 모든 DB데이터를 읽어서 메모리에서 페이징을 시도한다. (위험)
해결 방법
- XXXToOne 관계를 모드 페치 조인한다. (XXXToOne 관계는 row 수를 증가시키지 않으므로 영향 X)
- 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size, @BatchSize를 적용한다.
- hibernate.default_batch_fetch_size : 글로벌 설정
- @BatchSize : 개별 최적화
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN쿼리로 조회한다.
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
@GetMapping("/api/v3.1/orders")
public List<OrderDto> orderV3_page(
@RequestParam(value = "offset", defaultValue = "0") int offset, //시작위치
@RequestParam(value = "limit", defaultValue = "100") int limit) { //종료위치
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
}
OrderRepository
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
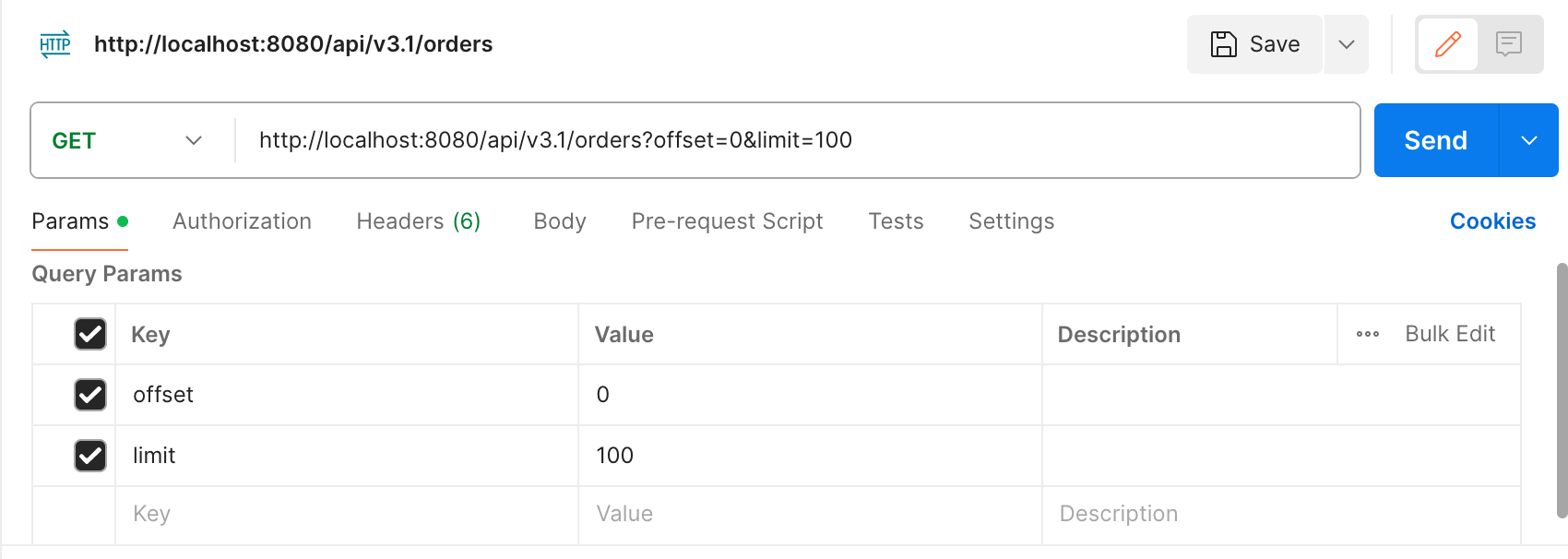
- Send를 누른 후 실행되는 쿼리의 수를 보자
- 페치 조인으로 Order, Member, Delivery를 불러오는 쿼리 1개
- 주문이 2개이므로 OrderItem을 불러오는 쿼리 2개
- 각 OrderItem에 Item이 2개씩 있으므로 Item을 불러오는 쿼리 2 + 2개 -> 4개
- 총 7개의 쿼리가 실행된다.
default_batch_fetch_size 적용하기

- application.yml에서 default_batch_fetch_size를 설정해준다.
batch size가 무엇일까?
- 위의 경우처럼 OrderItem을 조회하면 2개의 데이터가 나온다.
- 그렇다면 쿼리가 2번 실행이 되야한다는 것이다.
- 만약 여러개의 데이터를 쿼리 한 번에 조회해 온다면, 쿼리가 여러번 실행될 일이 없다.
- 이것을 가능하게 해주는게 batch size다.
- 조회해야할 데이터가 1000개라면 batch size를 100으로 설정하면 10번에 거쳐 모든 데이터를 가져올 것이다.
- 이때 batch size를 1000으로 설정해놓으면 단 한 번에 모든 데이터를 가져올 수 있다.
- batch size를 100으로 놓고 실행시켰을 때 실행되는 쿼리의 수를 보자
- 페치 조인으로 Order, Member, Delivery를 불러오는 쿼리 1개
- 주문이 2개이지만 OrderItem을 100개씩 불러오는 쿼리 1개
- 각 OrderItem에 Item이 2개씩 있으므로 총 4개지만 Item을 100개씩 불러오는 쿼리 1개
- 총 3개의 쿼리가 실행된다.
- N + 1 문제가 1 + 1로 최적화되었다.
- default_batch_fetch_size는 글로벌 설정이다.
- 개별로 설정하고 싶다면 @BatchSize를 사용하면 된다.
컬렉션에 적용할 때
@Entity
@Table(name = "orders")
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Order {
...
@BatchSize(size = 100) // batch size 설정
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems = new ArrayList<>();
...
}
컬렉션이 아닌 경우에 적용할 때
@BatchSize(size = 100) // batch size 설정
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
@Getter @Setter
public abstract class Item {
...
}
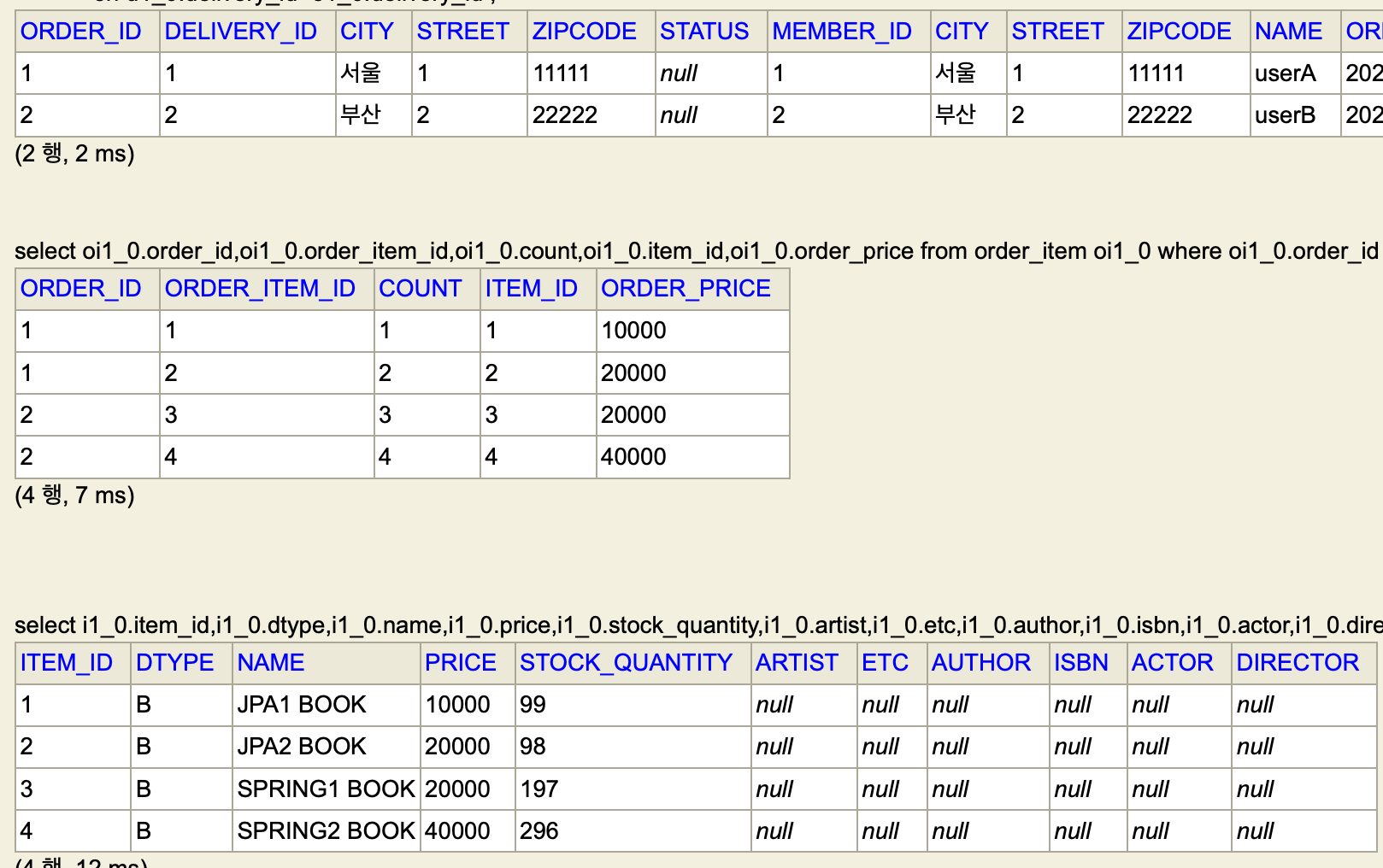
- 이렇게 적용한 후 실행된 쿼리를 직접 H2로 조회해보면
- 중복 데이터가 사라지고 가독성이 좋아졌다.
장점
- 쿼리 호출 수가 1 + N 에서 1 + 1로 최적화된다.
- 조인보다 DB 데이터 전송량이 최적화된다. (중복 데이터가 없다.)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 증가하지만, DB 데이터 전송량이 감소한다.
- 컬렉션 페치 조인은 페이징이 불가능하지만, 이 방법은 페이징이 가능하다.
참고
- default_batch_fetch_size의 크기는 100~1000 사이를 선택하는 것을 권장한다.
- 데이터베이스에 따라 IN절 파라미터를 1000으로 제한하기도 한다.
- 1000으로 설정하면 한번에 1000개를 DB에서 불러오므로 DB에 순간 부하가 증가할 수 있다.
- 하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량은 같다.
- 살살 10대 맞을지 세게 한 대 맞을지의 문제이다.
출처 : 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화
728x90
반응형
'JPA' 카테고리의 다른 글
| [JPA 활용] 컬렉션 조회 최적화 - 플랫 데이터 🐱 (0) | 2023.11.13 |
|---|---|
| [JPA 활용] 컬렉션 조회 최적화 - JPA에서 DTO 직접 조회 🐱 (0) | 2023.11.11 |
| [JPA 활용] 컬렉션 조회 최적화 - 엔티티를 DTO로 변환 🐱 (0) | 2023.11.10 |
| [JPA 활용] 조회 성능 최적화 - JPA에서 DTO로 조회🐱 (0) | 2023.11.10 |
| [JPA 활용] 조회 성능 최적화 - 엔티티를 DTO로 변환(페치 조인) 🐱 (0) | 2023.11.08 |
'JPA' Related Articles
more
